Искусственный интеллект как коллоидный раствор?
Последние годы поднят невероятный маркетинговый хайп вокруг ИИ. Не люблю этот маскирующий термин, к интеллекту отношения не имеющий.
Но что же скрывается под громкой вывеской ИИ?
На мой взгляд, это смесь разных технологий во многих случаях ранее тоже бывших предметом моды. Это и экспертные системы, и автоматизация построения моделей данных, построения онтологических моделей и генерация текстов и изображений, работа с большими объемами данных, обработка графических и видеоизображений, распознавание образов, беспилотные системы и так далее.
Просто стало удобно всё продавать под одной вывеской в одном большом черном мешке.
Ситуация напомнила питерского профессора химии, который за обедом смешивал в одной миске первое, второе и третье, объясняя это тем, что в желудке всё и так переходит в коллоидный раствор.
Это никак не философский камень или панацея от всех бед – надеюсь, время разделит и отсеет блуд.
Тем не менее, принято множество деклараций и законов в области регулирования ИИ.
Так, 2 февраля 2025 года вступили в действие первые нормы Закона об ИИ Европейского Союза. https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A32024R1689
Эта инициатива в регулировании напомнила о внедрении паровых котлов и индустриальную революцию XIX века.
Тогда после нескольких серьезных аварий для обеспечения безопасности паровых котлов на промышленных предприятиях и паровых двигателях было введено технологическое регулирование (например, для Германии — технадзор TЬV).
Что же пытаются регулировать и ограничить?
— Манипулятивные техники c поведением и решениями людей.
— Социальный рейтинг — оценка поведения или личности индивидов.
— Мониторинг биометрии в реальном времени в публичном пространстве.
— Обнаружение эмоций.
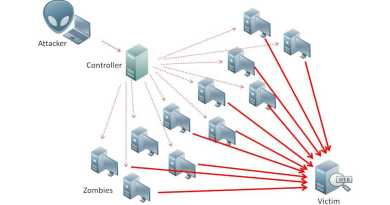
— Создание и использование крупномасштабных баз граждан, в частности, для мониторинга или отслеживания людей.
Но как раз по этим направлениям и сделан большой задел, накоплено много данных – и это задел представляет для многих интерес.
Также вызывает сомнение и качество данных. Не секрет, что доступная для обработки текстовая информация в Интернете уже не раз пройдена ботами ИИ, что вызывает вопросы к качеству накапливаемой информации.
В свою очередь растет и процент сгенерированного с помощью ИИ контента в сети. Как оценивать после этого результаты генеративного ИИ, основанные на обработке вторичного материала?
Конечно, начинают делаться попытки как-то ограничить это «загрязнение» – например, госорганы КНР вводят обязательную маркировку контента, сгенерированного ИИ, в том числе и для исключения его из дальнейшей обработки.
Как всегда, плодится и множество «пионеров» – адептов новой/старой религии – бегут – как пчёлы на мёд – в ожидании куша – как они делали это и ранее.
Не знаю, к чему всё это приведёт, но не теряю оптимизма.
Пережили луддитов и промышленную революцию, переживем и эту «искусственную»…
Паровые машины превратились в атомные электростанции, во что превратится ИИ – посмотрим…